
The purpose of this post is to expand upon a concept I first introduced during the Perfect Media Server - 2019 Edition. We’ll cover why you might want to consider this approach in first place, how to layout your disks and discuss how this will provide you the ultimate flexibility if you don’t want to fully commit to ZFS.
I won’t cover in great detail the concepts around ZFS because so many others have done it so well before me. Specifically I highly recommend giving this article by Jim Salter a read over at Ars Technica.
ZFS is more than just a filesystem. It merges parity calculation, data integrity checks and data storage into one layer that we happen to call a filesystem. The single biggest drawback to ZFS is that vdevs / pools are largely immutable once created. Adding new drives is hard and removing them is impossible. It’s just not designed for that. This causes issues for most home users who buy one or two drives a year as their collections grow.
Catastrophic performance implications or even data loss can occur with incorrectly architected pools. Mismatched drive sizes are not a good idea and ideally you don’t want to match drives of vastly differing performance characteristics either. Therefore the common wisdom is that when building out a ZFS pool you must build that pool (or vdev) as big as you think you’ll need it and usually this means buying 4+ drives at a time. This can quickly become very expensive.
Let’s also consider the purpose of the average home file server, the audience this article is largely aimed at. Most folks will probably have some media files that are easily replaced and then a second class of data which is irreplaceable. This irreplaceable data such as photographs, a music collection, documents, drone footage and so on is what I use ZFS to store. Everything else, the ephemeral ‘Linux ISO’ collection is stored using mergerfs and is protected against drive failures with SnapRAID. (SnapRAID is not backup!).
Technically, mergerfs doesn’t actually store anything. It provides a transparent layer that sits over the top of each data disk and merges them together under a single mountpoint. Data is stored on each individual filesystem in a JBOD fashion and is not striped nor is it checked for integrity. mergerfs also does not provide mitigation for drive failure, this is where SnapRAID comes in. It is used to calculate a snapshot of parity across all data drives that are not using ZFS. The ZFS drives are configured in a mirror and take care of their own parity and data integrity checks.
It’s best to think of these two classes of storage as entirely separate entities that handle their own redundancy and happen to be connected via mergerfs. In reality, they have nothing whatsoever to do with each other.
Drive layout
It’s time for an example. Below is an /etc/fstab entry that we will use to merge the filesystems mounted at /mnt/disk* as well as the ZFS datasets mounted at /mnt/tank/fuse. These are arbitrary paths and can be adjusted to your use case or dataset names.
/mnt/disk*:/mnt/tank/fuse /mnt/storage fuse.mergerfs defaults,allow_other,direct_io,use_ino,hard_remove,minfreespace=250G,fsname=mergerfs 0 0mergerfs supports globbing allowing us to mount multiple filesystems at once. Take the image below as an example, disk1, disk2, disk3, disk4 and disk5 will all be mounted at /mnt/storage because we specified /mnt/disk* in fstab. Furthermore our ZFS dataset at /mnt/tank/fuse will also be mounted at /mnt/storage too.
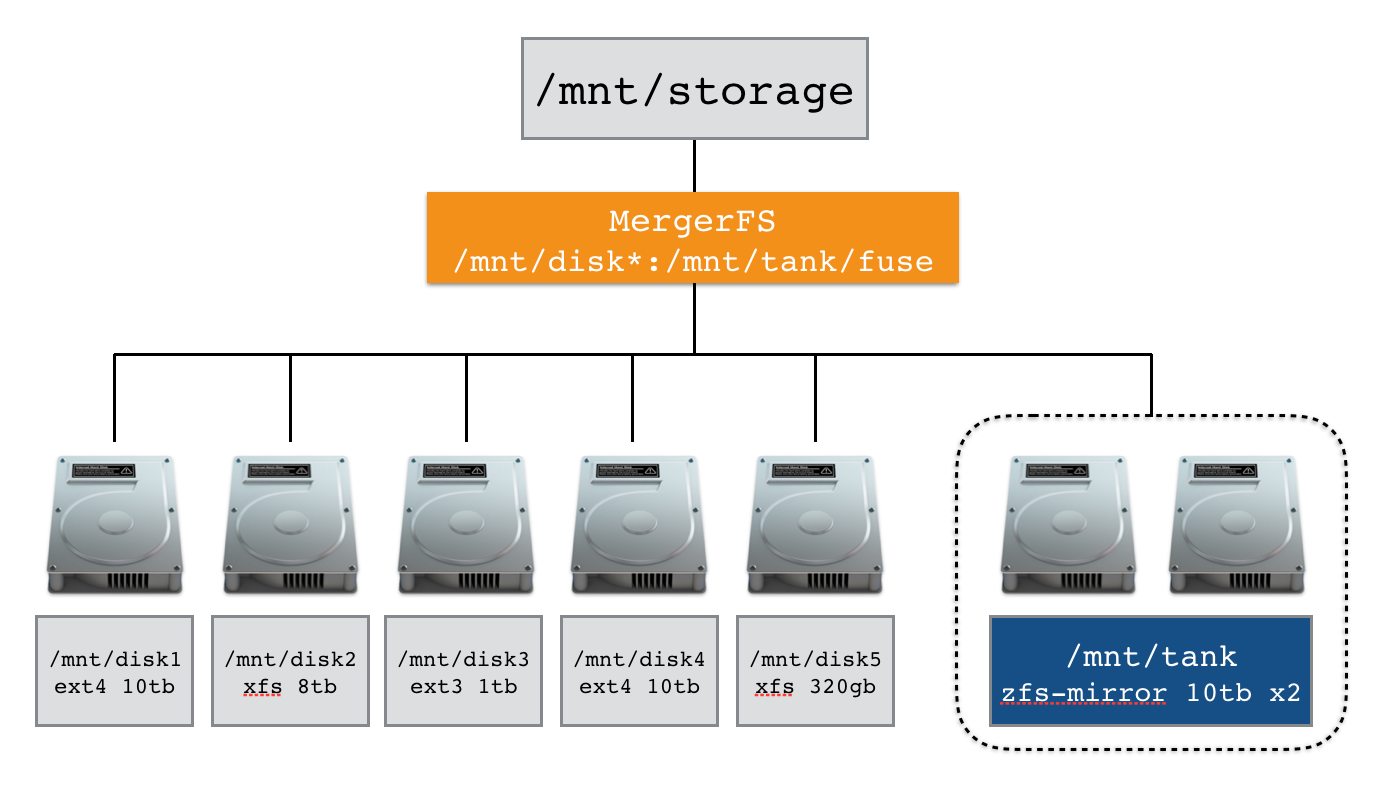
Here is an output from tree which shows this in action.
alex@cartman:/mnt$ tree -L 2
.
├── disk1
│ ├── movies
│ └── tv
├── disk2
│ └── movies
├── disk3
│ └── sports
├── storage
│ ├── drone
│ ├── movies
│ ├── music
│ ├── photos
│ ├── software
│ └── tv
└── tank
├── documents
│ └── notes
└── fuse
├── drone
├── music
├── photos
└── softwareAs you can see we now have data spread across multiple filesystems or physical disks that is merged transparently into /mnt/storage by mergerfs from drives with XFS, ext4 and ZFS. Note also how documents do not show under /mnt/storage because they are not in the fuse dataset.
Use of the correct create policy (the default of epmfs should suffice) in mergerfs is important to maintain this set up. When you create a new file mergerfs will look for an existing path with most free space (epmfs) and then create the file there. In this way we can maintain the logical separation we’ve created keeping some data on ZFS and other data on our JBOD ‘array’. It’s best to try and keep the directories you’d like on ZFS uniquely named from those you don’t so that mergerfs knows where to put them.
Conclusion
The real magic at work here is that mergerfs doesn’t care how the underlying data is stored. We get all the benefits of ZFS for our most critical data such as data integrity protection, snapshots using Sanoid and simple remote replication using syncoid. We also maintain the flexibility of a JBOD mergerfs based solution meaning we can store our more ephemeral data cheaply and without the relatively large commitment that building a multiple drive ZFS based media server would require.

Should you decide to change course completely in future, mergerfs will allow you to add or remove drives with zero penalty. It will either add or remove only the data on the removed drive from the equation. SnapRAID will protect you from drive failures (not ZFS drives) in your JBOD array.
I hope this article gave you some food for thought about your next storage build.